Kafka
Apache Kafka 是一个分布式数据流处理平台,可以实时发布、订阅、存储和处理数据流。完成 Agent 部署后,您可以跟随本文教程在 Tapdata 中添加 Apache Kafka 数据源,后续可将其作为源或目标库来构建数据管道。
支持版本
Kafka 2.3.x
使用限制
- 仅支持 JSON Object 字符串的消息格式,例如:
{"id":1, "name": "张三"}。 - 消息推送实现为 At least once,消费端需要设计幂等。
Kafka 消费说明
在后续配置数据复制/数据转换任务时,可选择数据的同步方式,对应的消费说明如下:
- 仅全量:从 Topic 中各分区的 earliest offset 开始订阅消费,如果之前存在消息消费记录,则恢复到之前的 offset 开始消费。
- 仅增量:从 Topic 中各分区的 latest offset 开始订阅消费,如果之前存在消息消费记录,则恢复到之前的 offset 开始消费。
- 全量 + 增量:跳过全量同步阶段,从增量阶段开始。
- 如果没有进行过全量同步,则会从 Topic 中各分区的 earliest offset 开始订阅消费,否则从 Topic 中各分区的 latest offset 开始订阅消费。
- 如果之前存在消息消费记录,则会恢复到之前的 offset 开始消费。
准备工作
-
登录 Kafka 所属设备。
-
(可选)如您将 Kafka 作为目标库,推荐提前创建好数据要存放的 Topic,如果由 Tapdata 自动创建,则其分区和副本数均为 1。
下述命令示例表示创建一个名为 kafa_demo_topic 的 Topic,其分区数和副本数均为 3:
bin/kafka kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic kafa_demo_topic更多介绍,见 Kafka 快速入门。
-
确认加密方式,如开启了 kerberos 认证,您还需要提前准备好密钥、配置等文件。
添加数据源
-
在左侧导航栏,单击连接管理。
-
在页面右侧,单击创建连接。
-
在跳转到的页面,单击认证数据源标签页,然后选择 Kafka。
-
根据下述说明完成数据源配置。
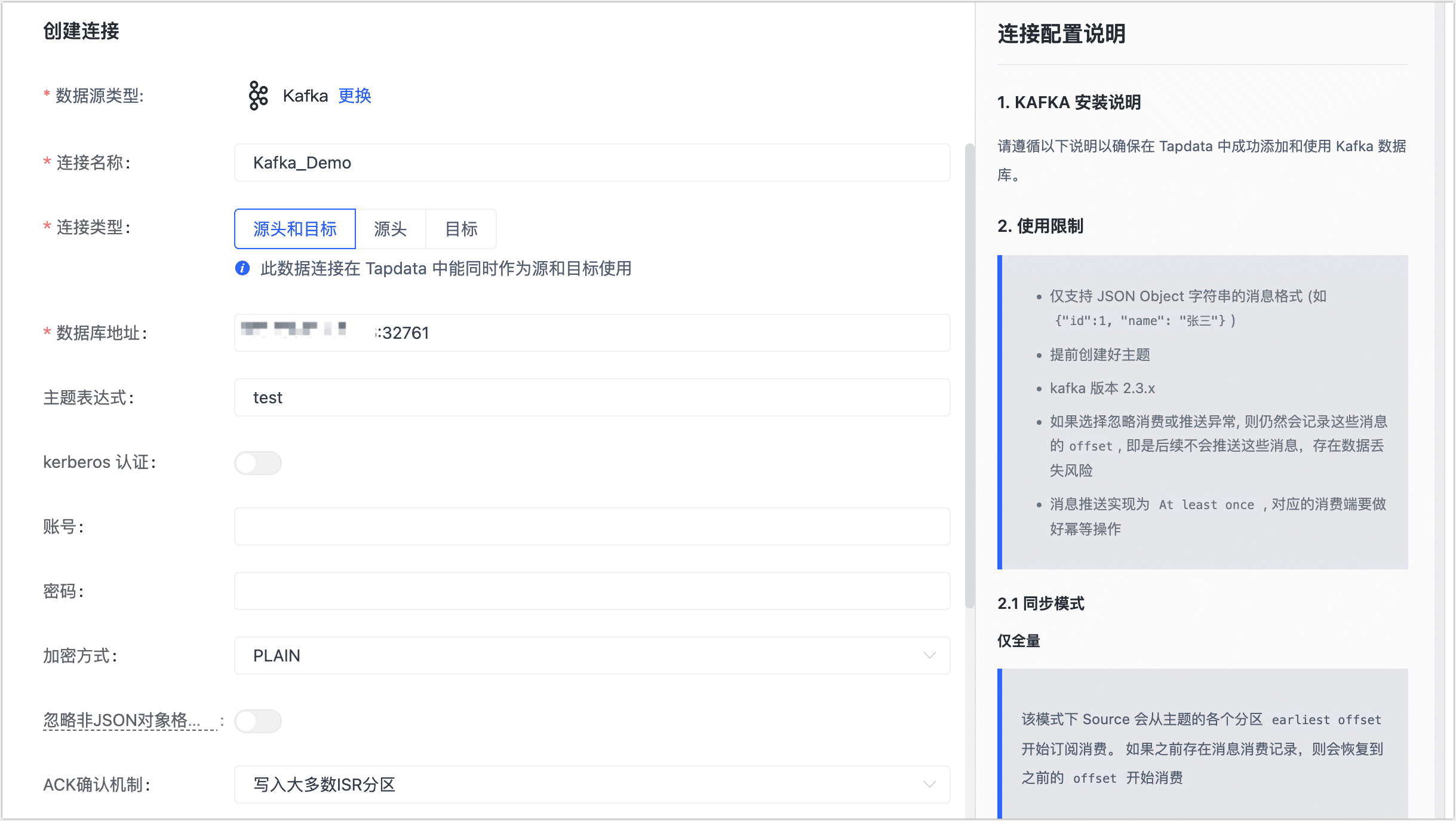
- 连接信息设置
- 连接名称:填写具有业务意义的独有名称。
- 连接类型:支持将 Kafka 作为源或目标库。
- 数据库地址:Kafka 连接地址,包含地址和端口号,两者之间用英文冒号(:)分隔,例如
113.222.22.***:9092。 - 主题表达式:Kafka 中的 Topic,支持正则表达式,长度不超过 256 个字符,Topic 创建方法,见 Kafka 快速入门。
- Kerberos 认证:如 Kafka 开启了该认证,您需要打开该开关,然后上传并设置密钥、配置等信息。
- 账号、密码、加密方式:如 Kafka 开启了密码认证,您需要填写账号和密码,选择加密方式。
- 高级设置
- 忽略非 JSON 对象格式消息:根据业务需求选择是否忽略,如果未忽略且遇到了该格式的消息,将停止拉取。
- ACK 确认机制:根据业务需求选择:不确认、仅写入 Master 分区、写入大多数 ISR 分区(默认)或写入所有 ISR 分区。
- 消息压缩类型:支持 gzip、snappy、lz4、zstd,消息量较大时可开启压缩以提高传输效率。
- 忽略推送消息异常:打开该开关后,系统仍会记录相关消息的 offset,但后续不会推送,可能存在数据丢失风险。
- 共享挖掘:挖掘源库的增量日志,可为多个任务共享源库的增量日志,避免重复读取,从而最大程度上减轻增量同步对源库的压力,开启该功能后还需要选择一个外存用来存储增量日志信息。
- Agent 设置:默认为平台自动分配,您也可以手动指定。
- 模型加载频率:数据源中模型数量大于 1 万时,Tapdata 将按照本参数的设定定期刷新模型。
- 连接信息设置
-
单击连接测试,测试通过后单击保存。
提示如提示连接测试失败,请根据页面提示进行修复。