PostgreSQL
PostgreSQL 是功能强大的开源对象关系数据库管理系统(ORDBMS),TapData 支持将 PostgreSQL 作为源或目标库,帮助您快速构建数据流转链路。接下来,我们将介绍如何在 TapData 平台中连接 PostgreSQL 数据源。
支持版本与架构
-
版本:PostgreSQL 9.4~16
-
架构:单节点或主从架构
提示主从架构下,如需读取从库的增量数据变更,需在配置数据源时选择 Walminer 插件来实现。
支持数据类型
| 类别 | 字段类型 |
|---|---|
| 字符串与文本 | character、character varying、text |
| 数值 | integer、bigint、smallint、numeric、real、double precision |
| 二进制 | bytea |
| 位 | bit、bit varying |
| 布尔 | boolean |
| 日期和时间 | timestamp without time zone、timestamp with time zone、date、time without time zone、time with time zone、interval |
| 空间数据类型 | geometry、point、polygon、circle、path、box、line、lseg |
| 网络地址类型 | inet、cidr、macaddr |
| 标识符类型 | uuid、oid、regproc、regprocedure、regoper、regoperator、regclass、regtype、regconfig、regdictionary |
| 文本搜索类型 | tsvector、tsquery |
| 其他 | xml、json、jsonb、array |
将 PostgreSQL 作为目标库或通过 Wal2json 插件获取其增量数据时,以下数据类型不受支持:tsvector、tsquery、regproc、regprocedure、regoper、regoperator、regclass、regtype、regconfig 和 regdictionary。如果使用 Walminer 插件,这些类型同样不受支持,此外还包括 array 和 oid 类型。
支持同步的操作
DML 操作:INSERT、UPDATE、DELETE
DDL 操作:新增字段、修改字段名、修改字段属性、删除字段
- 作为同步目标时,您可以通过任务节点的高级配置选择写入策略,如插入冲突时更新或丢弃、更新失败时插入或仅打印日志、启用文件写入方式等。此外,还可应用和执行源库解析的 ADD COLUMN、CHANGE COLUMN、DROP COLUMN 和 RENAME COLUMN 操作。
- 在 PostgreSQL 间数据同步的场景下,额外支持字段默认值、自增列和外键约束同步的能力;PostgreSQL 同步到 SQL Server 场景下,额外支持默认值和外键同步的能力。
功能限制
- PostgreSQL 作为源库时,使用 physical 日志插件不支持指定增量数据采集时间;使用 pgoutput、wal2json 或 decoderbufs 插件时,如需按指定时间启动增量同步,需将源节点高级特性中的 保留Wal小时数 设置为大于 0,并确保目标时间位于保留窗口内。
- 如需采集 PostgreSQL 源库的 DDL 事件,需使用 pgoutput、wal2json 或 decoderbufs 等逻辑复制插件,并在源节点高级特性中开启 启用DDL触发器。该能力会在源库默认创建
public._tapdata_ddl_audit审计表、事件触发器和触发器函数,要求同步账号具备创建事件触发器的权限(通常需要超级用户权限)。 - PostgreSQL 不支持字符串类型存放
\0,TapData 会将其自动过滤以避免异常报错。 - 如需捕获分区主表的增量事件,必须使用 PostgreSQL 13 及以上版本,并选择 pgoutput 插件。
- Walminer 插件目前仅支持连接合并共享挖掘。
注意事项
- 使用基于复制槽的日志插件(如 wal2json)时,过多的共享挖掘进程可能导致 WAL 日志积压,增加磁盘压力。建议减少挖掘进程数量或及时删除无用的 CDC 任务和复制槽。
- 由于 PostgreSQL 的逻辑复制依赖复制槽 (Replication Slot) 的创建,如果数据库中有正在运行的任务(如刷新物化视图),可能导致复制槽创建语句被阻塞,尤其当连接测试长时间无响应时,应及时排查此类任务。
- 基于 WAL 日志的插件(如 walminer)在执行共享挖掘时会频繁读写
walminer_contents表,从而产生一定负载,但因目前仅支持单任务挖掘,影响相对较小。
准备工作
作为源库
-
以管理员身份登录 PostgreSQL 数据库。
-
创建用户并授权。
-
执行下述格式的命令,创建用于数据同步/开发任务的账号。
CREATE USER username WITH PASSWORD 'password';- username:用户名。
- password:密码。
-
执行下述格式的�命令,授予账号权限。
- 仅读取全量数据
- 读取全量+增量数据
-- 进入要授权的数据库
\c database_name
-- 授予目标 Schema 的表读取权限
GRANT SELECT ON ALL TABLES IN SCHEMA schema_name TO username;
-- Grant USAGE permission to schema
GRANT USAGE ON SCHEMA schema_name TO username;-- 进入要授权的数据库
\c database_name
-- 授予目标 Schema 的表读取权限
GRANT SELECT ON ALL TABLES IN SCHEMA schema_name TO username;
-- 授予目标 Schema 的 USAGE 权限
GRANT USAGE ON SCHEMA schema_name TO username;
-- 授予复制权限
ALTER USER username REPLICATION;- database_name:数据库名称。
- schema_name:Schema 名称。
- username:用户名。
-
-
执行下述格式的命令,修改复制标识为 FULL(使用整行作为标识),该属性决定了当数据发生 UPDATE/DELETE 时,日志记录的字段。
提示如仅需读取 PostgreSQL 的全量数据,则无需本步骤及后续步骤。
ALTER TABLE 'schema_name'.'table_name' REPLICA IDENTITY FULL;- schema_name:Schema 名称。
- table_name:表名称。
-
登录 PostgreSQL 所属的服务器,根据业务需求和版本选择要安装的解码器插件:
-
Wal2json(推荐):适用于 PostgreSQL 9.4 及以上,将 WAL 日志转换为 JSON 格式,操作简单,需要源表包含主键,否则无法同步删除操作。
-
Pgoutput:PostgreSQL 10 引入的内置逻辑复制协议,无需额外安装。对于含主键表且
replica identity为default的情况,更新事件中的before字段会为空,可通过设置replica identity full解决。此外,如您未授予数据库级创建权限,需使用以下命令创建所需 PUBLICATION:CREATE PUBLICATION dbz_publication_root FOR ALL TABLES WITH (publish_via_partition_root = TRUE);
CREATE PUBLICATION dbz_publication FOR ALL TABLES;提示此外,在创建连接时选择 Pgoutput 插件,可开启部分订阅功能,避免无主键表必须设置 REPLICA IDENTITY FULL 才能更新/删除的限制;注意用于同步的账号需具备
CREATE PUBLICATION和目标表的OWNER权限。 -
Decoderbufs:适用于 PostgreSQL 9.6 及以上,利用 Google Protocol Buffers 解析 WAL 日志,但配置较为复杂。
-
Walminer:不依赖逻辑复制,无需设置
wal_level为logical,也不需要调整复制槽配置,但需授予超级管理员权限。此外,当 PostgreSQL 采用主从架构时,推荐使用 Walminer 插件读取增量数据,以保障主从切换过程中数据的完整性。
提示如需采集 PostgreSQL 源库的 DDL 事件,请选择 pgoutput、wal2json 或 decoderbufs 插件,并确保同步账号具备创建事件触发器的权限。TapData 会通过事件触发器将 DDL 写入
public._tapdata_ddl_audit审计表,再由逻辑复制槽采集该审计表的变更;如果账号权限不足或不需要采集 DDL,可在任务源节点高级特性中关闭 启用DDL触发器。接下来,我们以 Wal2json 为例演示安装流程。
提示本案例中,PostgreSQL 为 12 版本,安装在 CentOS 7 操作系统上,如您的环境与本案例不同,需要调整下述步骤中安装的开发包版本、环境变量的路径等。
-
添加仓库包。
yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm -
安装 PostgreSQL 12 开发包。
yum install -y postgresql12-devel -
设置环境变量并使其生效。
export PATH=$PATH:/usr/pgsql-12/bin
source /etc/profile -
安装环境依赖,包含 llvm、clang、gcc 等。
yum install -y devtoolset-7-llvm centos-release-scl devtoolset-7-gcc* llvm5.0 -
依次执行下述命令,完成插件的安装。
# 克隆并进入目录
git clone https://github.com/eulerto/wal2json.git && cd wal2json
# 进入 scl 的 devtoolset 环境
scl enable devtoolset-7 bash
# 编译安装
make && make install -
修改配置文件
postgresql.conf,将wal_level的值修改为logical。提示如果 PostgreSQL 的版本为 9.4, 9.5、9.6,还需调大
max_replication_slots和max_wal_senders的值(例如设置为 10)。 -
修改配置文件
pg_hba.conf,增加下述内容以保障 TapData 可访问到数据库。# 替换 username 为前面创建的用户名
local replication username trust
host replication username 0.0.0.0/32 md5
host replication username ::1/128 trust -
在业务低峰期,重启 PostgreSQL 服务。
service postgresql-12.service restart
-
-
(可选)测试日志插件。
-
连接 postgres 数据库,切换至需要同步的数据库并创建一张测试表。
-- 假设需要同步的数据库为 demodata,模型为 public
\c demodata
CREATE TABLE public.test_decode
(
uid integer not null
constraint users_pk
primary key,
name varchar(50),
age integer,
score decimal
); -
创建 Slot 连接,以 wal2json 插件为例。
SELECT * FROM pg_create_logical_replication_slot('slot_test', 'wal2json'); -
对测试表插入一条数据。
INSERT INTO public.test_decode (uid, name, age, score)
VALUES (1, 'Jack', 18, 89); -
监听日志并查看返回结果,是否有刚才插入操作的信息。
SELECT * FROM pg_logical_slot_peek_changes('slot_test', null, null);返回示例如下(竖向显示):
lsn | 0/3E38E60
xid | 610
data | {"change":[{"kind":"insert","schema":"public","table":"test_decode","columnnames":["uid","name","age","score"],"columntypes":["integer","character varying(50)","integer","numeric"],"columnvalues":[1,"Jack",18,89]}]} -
确认无问题后,可销毁 Slot 连接并删除测试表。
SELECT * FROM pg_drop_replication_slot('slot_test');
DROP TABLE public.test_decode;
-
-
(可选)如需使用最后更新时间戳的方式进行增量同步,您需要执行下述步骤。
-
在源数据库中,执行下述命令创建公共函数,需替换 schema 名称。
CREATE OR REPLACE FUNCTION schema_name.update_lastmodified_column()
RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
NEW.last_update = now();
RETURN NEW;
END;
$$; -
创建字段和 trigger,每个表均需执行一次,例如表名为 mytable。
// 创建 last_update 字段
ALTER TABLE schema_name.mytable ADD COLUMN last_udpate timestamp DEFAULT now();
// 创建 trigger
CREATE TRIGGER trg_uptime BEFORE UPDATE ON schema_name.mytable FOR EACH ROW EXECUTE PROCEDURE
update_lastmodified_column();
-
作为目标库
-
以管理员身份登录 PostgreSQL 数据库。
-
执行下述格式的命令,创建用于数据同步/开发任务的账号。
CREATE USER username WITH PASSWORD 'password';- username:用户名。
- password:密码。
-
执行下述格式的命令,为数据库账号授予权限。
-- 进入要授权的数据库
\c database_name;
-- 授予目标 Schema 的 USAGE 和 CREATE 权限
GRANT CREATE,USAGE ON SCHEMA schemaname TO username;
-- 授予目标 Schema 的表读写权限
GRANT SELECT,INSERT,UPDATE,DELETE,TRUNCATE ON ALL TABLES IN SCHEMA schemaname TO username;
-- 如果源到目标存在外键关系的同步或需禁用目标表触发器时,需授权用户忽略外键约束(超级用户可跳过)
-- 如需恢复外键和触发器约束,则将其值从 replica 设为 origin
alter user username set session_replication_role = 'replica';
-- 由于 PostgreSQL 自身限制,对于无主键表需要执行下面命令才可正常使用更新和删除(TapData 会自动执行)
ALTER TABLE schema_name.table_name REPLICA IDENTITY FULL;- database_name:数据库名称。
- schema_name:Schema 名称。
- username:用户名。
开启 SSL 连接(可选)
为进一步提升数据链路的安全性,您还可以选择为 PostgreSQL 数据库开启 SSL(Secure Sockets Layer)加密,实现在传输层对网络连接的加密,在提升通信数据安全性的同时,保证数据的完整性。
-
登录 PostgreSQL 数据库所属的设备,依次执行下述命令创建自签名证书。
# 生成根证书私钥( pem文件)
openssl genrsa -out ca.key 2048
# 生成根证书签发申请文件(csr 文件)
openssl req -new -key ca.key -out ca.csr -subj "/C=CN/ST=myprovince/L=mycity/O=myorganization/OU=mygroup/CN=myCA"
# 创建自签发根证书,有效期为一年:
openssl x509 -req -days 365 -extensions v3_ca -signkey ca.key -in ca.csr -out ca.crt -
依次执行下述命令,生成服务端私钥和证书。
# 生成服务端私钥
openssl genrsa -out server.key 2048
# 生成服务端证书请求文件
openssl req -new -key server.key -out server.csr -subj "/C=CN/ST=myprovince/L=mycity/O=myorganization/OU=mygroup/CN=myServer"
# 使用自签 CA 证书签发服务端证书,有效期为一年
openssl x509 -req -days 365 -extensions v3_req -CA ca.crt -CAkey ca.key -CAcreateserial -in server.csr -out server.crt -
(可选)执行
openssl verify -CAfile ca.crt server.crt命令,验证服务端证书是否正确签署。 -
依次执行下述命令,生成客户端私钥和证书。
# 生成��客户端私钥
openssl genrsa -out client.key 2048
# 生成证书请求文件 ,为user1生成(完整认证时需要关注用户)
openssl req -new -key client.key -out client.csr -subj "/C=CN/ST=myprovince/L=mycity/O=myorganization/OU=mygroup/CN=user1"
# 使用根证书签发客户端证书
openssl x509 -req -days 365 -extensions v3_req -CA ca.crt -CAkey ca.key -CAcreateserial -in client.csr -out client.crt -
(可选)执行
openssl verify -CAfile ca.crt client.crt命令,验证客户端证书是否正确签署。 -
修改下述 PostgreSQL 配置文件,增加配置以启用 SSL 并指定相关证书/密钥文件。
- postgresql.conf
- pg_hba.conf
ssl = on
ssl_ca_file = 'ca.crt'
ssl_cert_file = 'server.crt'
ssl_crl_file = ''
ssl_key_file = 'server.key'
ssl_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL' # allowed SSL ciphers
ssl_prefer_server_ciphers = onhostssl all all all trust clientcert=verify-ca
连接 PostgreSQL
-
在左侧导航栏,单击连接管理。
-
单击页面右侧的创建。
-
在弹出的对话框中,搜索并选择 PostgreSQL。
-
在跳转到的页面,根据下述说明填写 PostgreSQL 的连接信息。
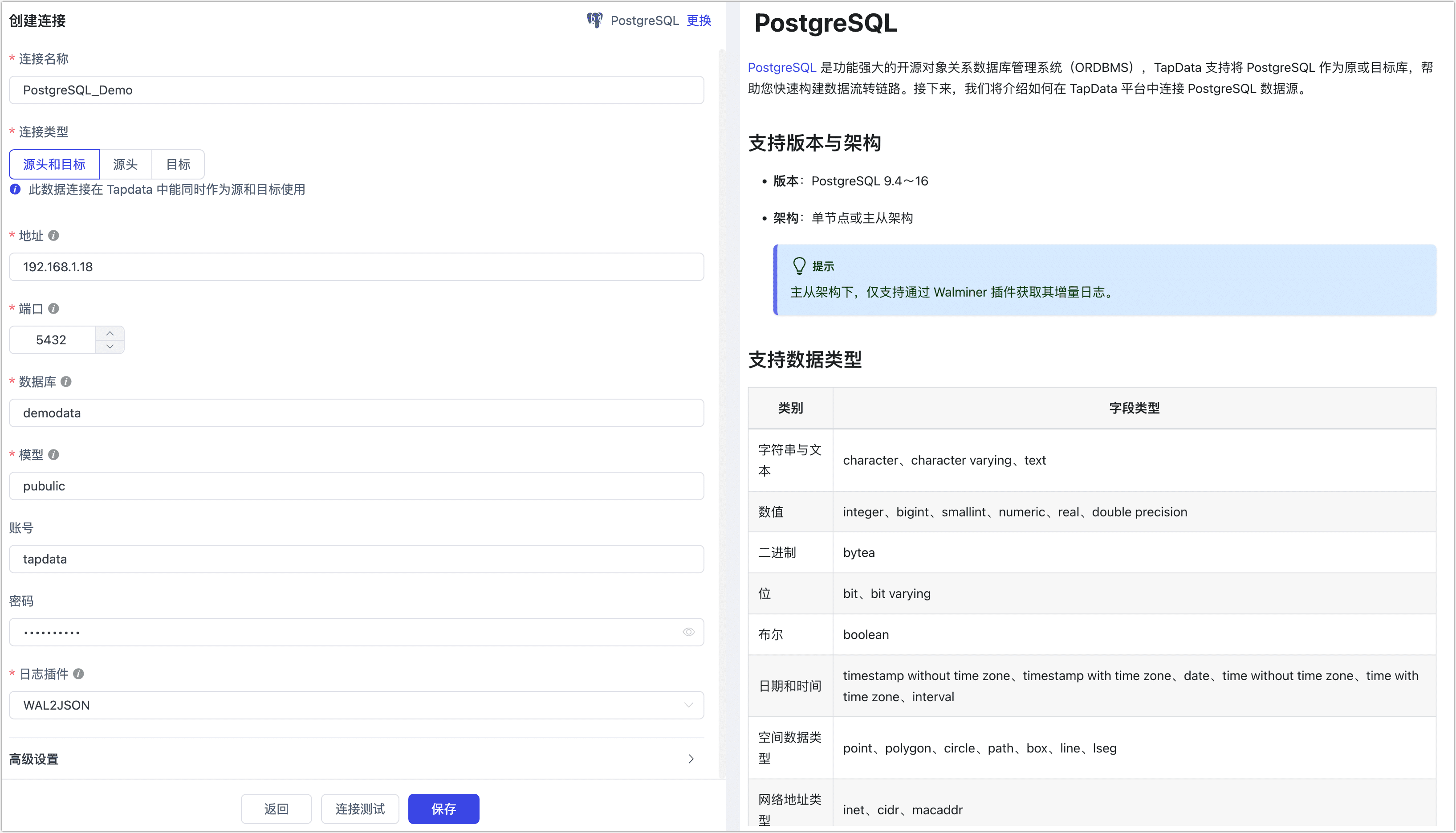
- 连接信息设置
- 连接名称:填写具有业务意义的独有名称。
- 连接类型:支持将 PostgreSQL 作为源或目标库。
- 地址:数据库连接地址。
- 端口:数据库的服务端口。
- 数据库:数据库名称,即一个连接对应一个数据库,如有多个数据库则需创建多个数据连接。
- 模型:Schema 名称。
- 账号:数据库的账号。
- 密码:数据库账号对应的密码。
- 日志插件:如需读取 PostgreSQL 的数据变更,实现增量数据同步,您需要根据准备工作的指引,完成插件的选择和安装。
- 部分订阅:仅在日志插件选择为Pgoutput时,支持开启该功能。开启后会为每张采集表独立创建 publication,避免全局 publication 造成无主键表必须设置
REPLICA IDENTITY FULL才能更新/删除的限制,但需数据库账号具备CREATE PUBLICATION权限及目标表的OWNER权限。
- 高级设置
- 额外参数:额外的连接参数,默认为空。
- 时区:默认为 0 时区,如果更改为其他时区,不带时区的字段(如 TIMESTAMP)会受到影响,而带时区的字段(如 TIMESTAMP WITH TIME ZONE)和 DATE 类型则不会��受到影响。
- 共享挖掘:挖掘源库的增量日志,可为多个任务共享源库的增量日志,避免重复读取,从而最大程度上减轻增量同步对源库的压力,开启该功能后还需要选择一个外存用来存储增量日志信息。
- 包含表:默认为全部,您也可以选择自定义并填写包含的表,多个表之间用英文逗号(,)分隔。
- 排除表:打开该开关后,可以设定要排除的表,多个表之间用英文逗号(,)分隔。
- Agent 设置:默认为平台自动分配,您也可以手动指定 Agent。
- 模型加载时间:如果数据源中的模型数量少于10000个,则每小时更新一次模型信息。但如果模型数量超过10000个,则刷新将在您指定的时间每天进行。
- 开启心跳表:当连接类型选择为源头和目标、源头时,支持打开该开关,任务引用并该数据源并启动后,由 TapData 在源库中创建一个名为 _tapdata_heartbeat_table 的心跳表并每隔 10 秒更新一次其中的数据(数据库账号需具备相关权限),用于数据源连接与任务的健康度监测。
- SSL 设置:选择是否开启 SSL 连接数据源,可进一步提升数据安全性,开启该功能后还需要上传 CA 文件、客户端证书、密钥填写客户端密码。
- 连接信息设置
-
单击连接测试,测试通过后单击保存。
提示如提示连接测试失败,请根据页面提示进行修复。
节点高级特性
在配置数据复制/转换任务时,将 PostgreSQL 作为源或目标节点时,为更好满足业务复杂需求,最大化发挥性能,TapData 为其内置更多高级特性能力,您可以基于业务需求配置:
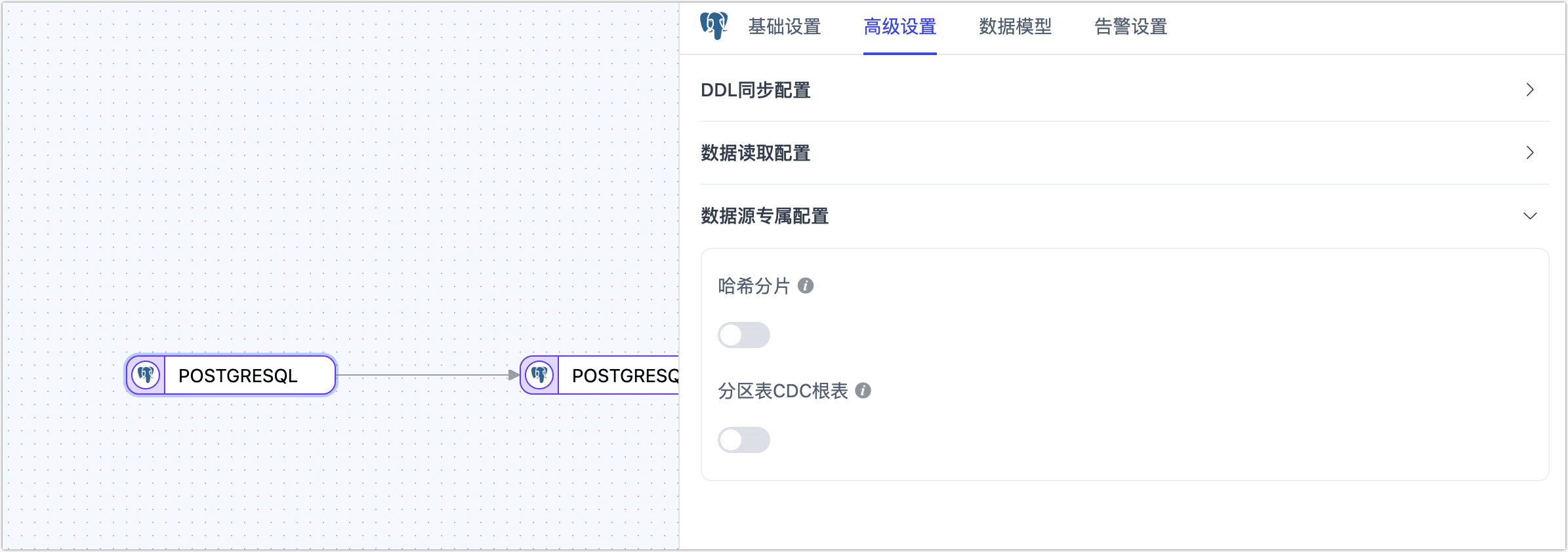
- 作为源节点
- 哈希分片:开启后,全表数据将在全量同步阶段按哈希值拆分为多个分片,并发读取数据,显著提升读取性能,但也会增加数据库负载,最大分片数可在启用开关后手动设置。
- 分区表 CDC 根表:仅在 PostgreSQL 13 及以上版本,并选择 pgoutput 日志插件时支持配置。开启时,仅感知根表的 CDC 事件;关闭时,仅感知子表的 CDC 事件。
- 最大队列大小:指定 PostgreSQL 读取增量数据队列大小,�默认为 8000,如果下游同步较慢或表的单条数据过大,请调低此配置。
- 启用DDL触发器:默认开启。开启后,TapData 会在源库默认创建
public._tapdata_ddl_audit审计表、DDL 事件触发器和触发器函数,将源库 DDL 写入审计表并通过逻辑复制槽采集,支持采集新增字段、字段改名、字段属性变更和删除字段事件;如果同步账号权限不足或无需采集 DDL,可手动关闭。 - 保留Wal小时数:默认值为 0,单位为小时。用于保留基于逻辑复制的 CDC checkpoint 与 WAL 推进窗口;设置为 0 时不保留历史 checkpoint,设置为大于 0 后,TapData 可在保留窗口内按指定增量时间点启动,保留时间越长,源库 WAL 占用可能越高。
- 修改唯一键拆分:默认开启。用于处理唯一键字段更新时,将 UPDATE 拆分为 DELETE + INSERT 事件,增强对目标端兼容性;如需保留原始 UPDATE 事件(例如用于审计或变更追踪),可手动关闭。
- 作为目标节点
- 忽略 NotNull:默认关闭,即在目标库建表时忽略 NOT NULL 的限制。
- 指定表所有者:同步至 PostgreSQL 时,可指定自动创建表的拥有者,需确保用于数据同步的账号具备相应的权限。如未授权,可以通过管理员身份登录数据库,执行
ALTER USER <tapdataUser> INHERIT;以及GRANT <tableOwner> TO <tapdataUser>;。 - 同步自增列:在 PostgreSQL 10 及以上版本时,启用该选项可将源数据库的自增列属性同步至目标表,使用
GENERATED BY DEFAULT AS IDENTITY方式生成唯一递增值。 - 自增键跳跃:适用于启用 同步自增列 时,可能出现自增 ID 间隙(如 1, 2, 4, 5,缺少 3),通常因数据库缓存或重启导致。默认值
1000000,表示预分配编号提升性能,事务回滚或重启可能造成编号跳跃,但不影响其唯一性。 - 应用默认值:默认关闭,开启后可同步字段默认值,适用于普通字符串和数值。异构数据源同步时,表达式和函数适配有限,目前支持
CURRENT_TIMESTAMP、CURRENT_USER、gen_random_uuid()等。 - 启用文件输入:默认关闭。启用后,TapData 基于 COPY 方法以文件形式高效批量写入数据,避免约束冲突导致的性能下降,显著提升大数据量同步效率。注意此场景下不支持二进制数据类型(bytea)。
常见问题
-
问:为什么 PostgreSQL 作为数据源的任务,重置会提示失败?
答:任务在重置或删除时,TapData 需要清理数据库中逻辑复制的 SLOT,如果此时 PostgreSQL 库无法连接,可能会重置失败。
-
问:TapData 任务运行后,PostgreSQL 中出现了很多 SLOT,这些可以清理吗?
答:每个任务使用基于复制槽的日志插件时,如果暂时停止任务,会在 PostgreSQL 中留下一个 SLOT。如果清理这些 SLOT,可能会导致任务重启时丢失 offset,从而数据不完整。如果任务不再需要,可以重置或删除任务,以便及时清理 SLOT。此外,如果使用其他基于复制槽的同步工具,可能�会出现复制槽无法被清理的情况,需要手动处理。
-
问题:当 CDC 意外中断后,可能导致 SLOT 连接无法从 PostgreSQL 主节点删除,如何清理?
答:可登录主节点,删除相关 SLOT 避免一直占用,清理方式如下:
-- 查看是否有 slot_name=tapdata 的信息
TABLE pg_replication_slots;
-- 删除 Slot 节点
select * from pg_drop_replication_slot('tapdata');