Dummy
Dummy 是测试数据源,可以生成测试数据。本文介绍如何在 Tapdata 中添加 Dummy 数据源。
支持的生成字段类型
| 类型 | 说明 | 参数 |
|---|---|---|
| array | 数组 | 无 |
| binary | 字节 | 无 |
| boolean | 布尔值 | 无 |
| date | 日期 | 无 |
| datetime | 时期+时间 | 无 |
| map | 键值对 | 无 |
| now | 当前时间 | 无 |
| number[(precision,scale)] | 数值 | ● precision: 长度(范围 1-40,默认 4) ● scale: 精度(范围 0-10,默认 1) |
| rdatetime[(fraction)] | 指定精度的日期 | fraction: 时间精度(默认:0,范围 0-9 整数) |
| rlongbinary[(byte)] | 指定长度的随机二进制 | byte: 字节长度(默认:1000) |
| rlongstring[(byte)] | 指定长度的随机长字符 | byte: 字节长度(默认:1000) |
| rnumber[(precision)] | 随机数字 | precision: 长度(默认:4) |
| rstring[(byte)] | 指定长度的随机字符 | byte: 字节长度(默认:64) |
| serial[(begin,step)] | 自增序列 | ● begin: 开始位置(默认:1) ● step: 步长(默认:1) |
| string(byte) | 字符串 | ● byte: 字节长度(默认:64) ● fixed: 如果定长字符器加上此标识(默认:非定长) |
| time | 时间 | 无 |
| uuid | UUID,即通用唯一识别码 | 无 |
操作步骤
-
在左侧导航栏,单击连接管理。
-
单击页面右侧的创建。
-
在弹出的对话框中,搜索并选择 Dummy。
-
在跳转到的页面,根据下述说明填写连接信息。
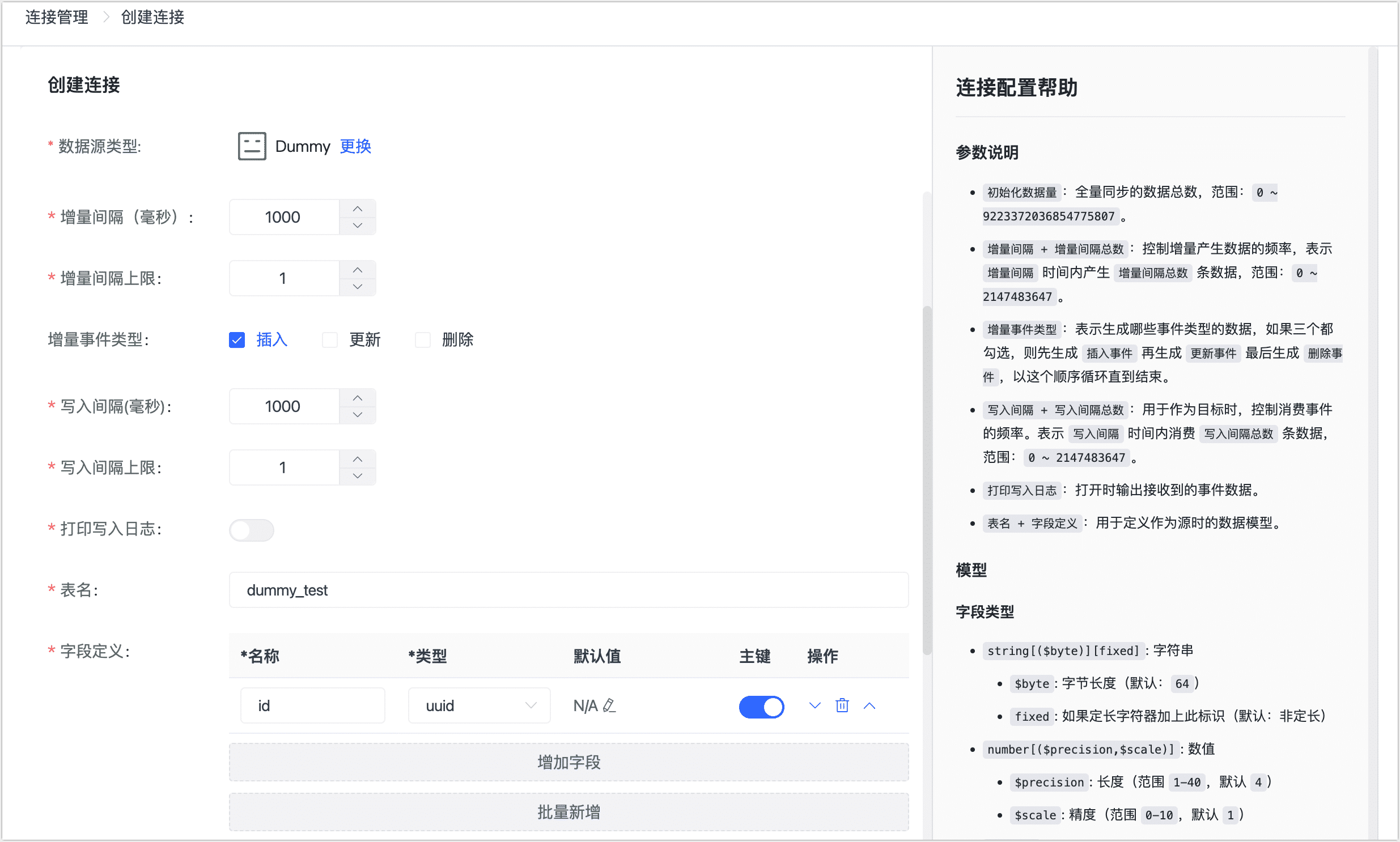
-
连接名称:填写具有业务意义的独有名称。
-
连接类型:选择源头或目标,也可以选择源头和目标。
-
初始化数据量:全量同步的数据总数,范围:0 ~ 9223372036854775807。
-
增量间隔、增量间隔上限:控制增量产生数据的频率,表示增量间隔时间内产生的增量间隔总数条数据,范围:0 ~ 2147483647。
-
增量事件类型:表示生成哪些事件类型的数据,如果全选,则以插入事件 > 更新事件 > 删除事件 的顺序循环。
-
写入间隔:作为目标数据源时,控制消费事件的频率,单位为毫秒,
-
写入间隔总数:表示 写入间隔 时间内消费 写入间隔总数条数据,范围 0 ~ 2147483647。
-
打印写入日志:打开时输出接收到的事件数据。
-
表名、字段定义:定义作为源头时表的结构,支持批量新增字段。
-
包含表:默认为全部,您也可以选择自定义并填写包含的表,多个表之间用英文逗号(,)分隔。
-
排除表:打开该开关后,可以设定要排除的表,多个表之间用英文逗号(,)分隔。
-
agent 设置:默认为平台自动分配,您也可以手动指定 Agent 。
-
模型加载时间:当数据源中模型数量小于 10,000 时,每小时刷新一次模型信息;如果模型数据超过 10,000,则每天按照您指定的时间刷新模型信息。
-
开启心跳表:当连接类型选择为源头和目标、源头时,支持打开该开关,由 Tapdata 在源库中创建一个名为 _tapdata_heartbeat_table 的心跳表并每隔 10 秒更新一次其中的数据(数据库账号需具备相关权限),用于数据源连接与任务的健康度监测。
提示数据源需在数据复制/开发任务引用并启动后,心跳任务任务才会启动,此时您可以再次进入该数据源的编辑页面,即可单击查看心跳任务。
-
-
单击连接测试,测试通过后单击保存。
提示如提示连接测试失败,请根据页面提示进行修复。