GaussDB(DWS)
数据仓库服务 GaussDB(DWS)是完全托管的企业级云上数据仓库服务,具备免运维、在线扩展、高效的多源数据加载能力,兼容 PostgreSQL 生态。TapData 支持将 GaussDB(DWS) 作为源和目标库,帮助您快速构建数据链路。接下来,我们将介绍如何在 TapData 平台中连接 GaussDB(DWS) 数据源。
支持版本与架构
- 版本:GaussDB(DWS) 8.1.3
- 架构:单机或集群架构
支持数据类型
| 类型 | 数据类型 |
|---|---|
| 字符串 | VARCHAR、VARCHAR2、TEXT、CHAR、NVARCHAR2 |
| 数值 | INTEGER、BIGINT、SMALLINT、NUMERIC、DECIMAL、REAL、DOUBLE PRECISION |
| 布尔类型 | BOOLEAN |
| 日期和时间类型 | TIMESTAMP、TIMESTAMP WITH TIME ZONE、TIMESTAMP WITHOUT TIME ZONE、TIME、TIME WITH TIME ZONE、TIME WITHOUT TIME ZONE、INTERVAL |
| 二进制 | BYTEA |
| 位串 | BIT、BIT VARYING |
| 网络 | CIDR、INETMACADDR |
| 几何 | POINT、LSEG、BOX、PATH、POLYGON、CIRCLE |
| 其他 | UUID、XML、JSON、JSONB |
支持同步的操作
- DML:INSERT、UPDATE、DELETE
- DDL(仅在作为目标时支持):ADD COLUMN、CHANGE COLUMN、DROP COLUMN、RENAME COLUMN
提示
- 作为源库时,增量数据同步需通过字段轮询的方式实现,且不支持采集 DDL 操作,详见变更数据捕获(CDC)。
- 作为目标库时,您还可以通过任务节点的高级配置,选择 DML 写入策略:插入冲突场景下,可选择转为更新或丢弃;更新失败场景下,可选择转为插入或仅打印日志。
功能限制
- 将集群架构的 GaussDB(DWS)作为源库进行增量同步时,尚不支持 CDC 的高可用机制。若发生主节点切换,增量同步可能出现异常或中断。
- 同步无主键表至 GaussDB(DWS)时,如不指定分布列,需要关闭目标端更新条件的唯一索引功能,避免因建表限制导致失败。
- GaussDB(DWS)默认将主键作为分布列。如需手动指定,分布列字段必须包含在主键、唯一索引或更新条件中,否则建表会失败。
- 若源端存在超出 GaussDB(DWS)限制的操作(如修改分布列),DWS 会将更新事件转为先删除后插入。此操作要求源端更新事件的
After数据字段齐全,例如 Oracle 需开启全字段补全日志功能。
什么是分布列
在 GaussDB(DWS) 中,分布列是指分布表中用于数据分布的列,它决定了数据在分布式存储中的分布方式并影响查询性能。更多介绍,见分布列选择最佳实践。
准备工作
-
登录 GaussDB(DWS)数据库,执行下述格式的命令,创建用于数据同步/转换任务的账号。
CREATE USER username WITH PASSWORD 'password';- username:用户名。
- password:密码。
-
为刚创建的账号授予权限。
- 作为源库
- 作为目标库
-- 进入要授权的数据库
\c database_name
-- 授予 USAGE 权限和 Schema 中表的读取权限
GRANT USAGE ON SCHEMA schema_name TO username;
GRANT SELECT ON ALL TABLES IN SCHEMA schema_name TO username;-- 进入要授权的数据库
\c database_name;
-- 授予目标 Schema 的 USAGE 和 CREATE 权限
GRANT CREATE,USAGE ON SCHEMA schemaname TO username;
-- 授予目标 Schema 的表读写权限
GRANT SELECT,INSERT,UPDATE,DELETE,TRUNCATE ON ALL TABLES IN SCHEMA schemaname TO username;
-- 授予目标 Schema 的 USAGE 权限
GRANT USAGE ON SCHEMA schema_name TO username;
-- 由于 GaussDB(DWS)自身限制,TapData 会对无主键表授予下述权限以保证可正常更新/删除数��据
-- ALTER TABLE schema_name.table_name REPLICA IDENTITY FULL;- database_name:数据库名称。
- schema_name:Schema 名称。
- username:用户名。
连接 GaussDB
-
在左侧导航栏,单击连接管理。
-
单击页面右侧的创建。
-
在弹出的对话框中,搜索并选择 GaussDB(DWS)。
-
在跳转到的页面,根据下述说明填写 GaussDB(DWS) 的连接信息。
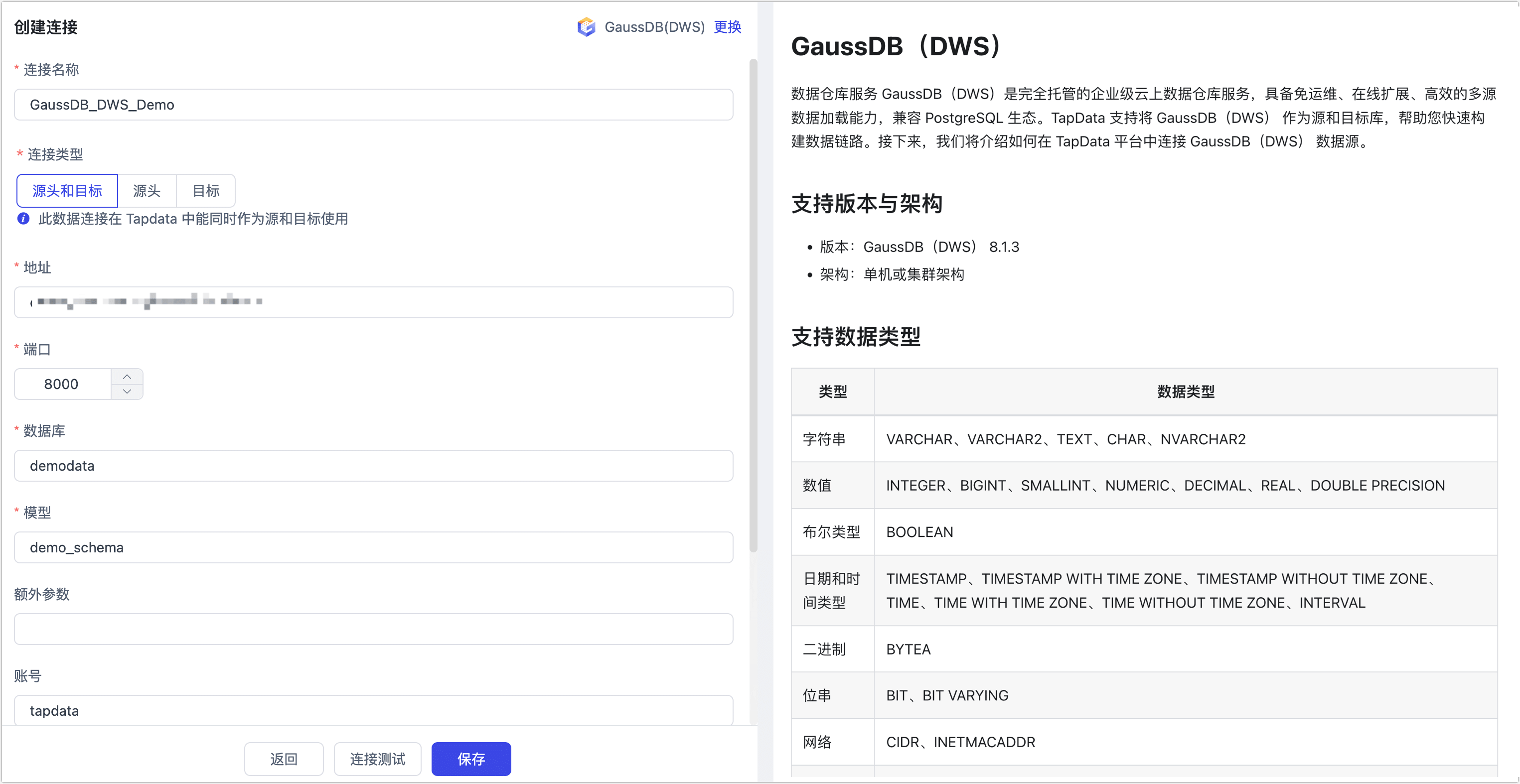
- 连接信息设置
- 连接名称:填写具有业务意义的独有名称。
- 连接类型:支持将 GaussDB(DWS)作为源或目标库。
- 地址:数据库服务的连接地址,更多介绍,见获取集群连接地址。
- 端口:数据库的服务端口。
- 数据库:数据库名称,即一个连接对应一个数据库,如有多个数据库则需创建多个数据连接。
- 模型:模型(Schema)名称。
- 额外参数:额外的连接参数,默认为空。
- 账号、密码:分别填写数据库的账号和密码。
- 时区:默认为 0 时区,如果更改为其他时区,不带时区的字段(如 TIMESTAMP)会受到影响,而带时区的字段(如 TIMESTAMP WITH TIME ZONE)和 DATE 类型则不会受到影响。
- 高级设置
- 包含表:默认为全部,您也可以选择自定义并填写包含的表,多个表之间用英文逗号(,)分隔。
- 排除表:打开该开关后,可以设定要排除的表,多个表之间用英文逗号(,)分隔。
- Agent 设置:默认为平台自动分配,您也可以手动指定 Agent。
- 模型加载时间:如果数据源中的模型数量少于10,000个,则每小时更新一次模型信息。但如果模型数量超过10,000个,则刷新将在您指定的时间每天进行。
- 连接信息设置
-
单击页面下方的连接测试,提示通过后单击保存。
提示如提示连接测试失败,请根据页面提示进行修复。
节点高级特性
在配置数据同步/转换任务时,将 GaussDB(DWS) 作为源或目标节点时,为更好满足业务复杂需求,最大化发挥性能,TapData 为其内置更多高级特性能力,您可以基于业务需求配置:
- 忽略 NotNull:默认开启,为避免空字符串在 GaussDB(DWS)中存为
NULL而导致与 NOT NULL 约束冲突,默认创建字符串类型字段时不加 NOT NULL 限制。若业务无需处理空字符串,可关闭此功能。 - 替换空字符:用于解决主键场景下的空字符问题,可通过该配置将空字符替换为指定值。
- 分布列:支持指定
distribute by hash进行均匀分布,分布字段需包含在主键或更新条件中。 - 启用文件输入:开启后采用文件流导入以提升性能,但不支持二进制类型或约束冲突的场景。