产品运维
本文列出 TapData Enterprise 运维相关的常见问题。
如何进行 TapData 健康检查?
此检查清单用于验证 TapData 服务是否处于健康运行状态。
-
在左侧导航栏,选择系统管理 > 集群管理,查看各组件的运行状态,主要检查:
- TapData 服务相关进程:Tapdata管理器、Tapdata引擎、Tapdata API服务器是否运行正常。
- 检查 CPU 和内存使用率是否处于健康水平(低于70%)
-
单击左侧导航栏的数据复制或数据转换,查看任务列表,主要检查各任务的状态是否均为运行中。 此外,您还可以单击任务名称,查看任务详细监控信息,确认任务运行正常,同步延迟是否在可接受范围内,任务 QPS 是否大于0。 如果任务出现异常,请跟随下述步骤排查:
- 检查任务报错信息:如果遇到任务异常,您可以通过任务的监控页面的底部查看相关日志信息,根据日志提示进行故障排除。更多介绍,见任务故障排查。
- 检查任务关联的数据库连接:单击左侧的连接管理,找到对应的数据源连接,单击其测试连接按钮以验证连通性,如遇异常,请根据提示进行故障排除(如密码错误)。
- 检查任务增量延迟:如果 QPS 突增持续 30 分钟以上,可能是源端批量操作或业务高峰引起,请评估任务是否需扩容;如果目标库无增量写入或写入耗时异常,请检查 CDC 的前提准备是否正确设置,以 MySQL 数据库为例,需确认是否开启了 binlog 并设置为 ROW 模式,具体设置可参考对应的创建连接文档。此外,任务日志中如出现主键冲突,需确认是否有配置改动。
如经过上述流程排查,任务仍异常,请联系 Tapdata 支持。
如何启停服务?
登录 TapData 平台后,在系统管理 > 集群管理中,可选择要目标服务,执行启停服务。
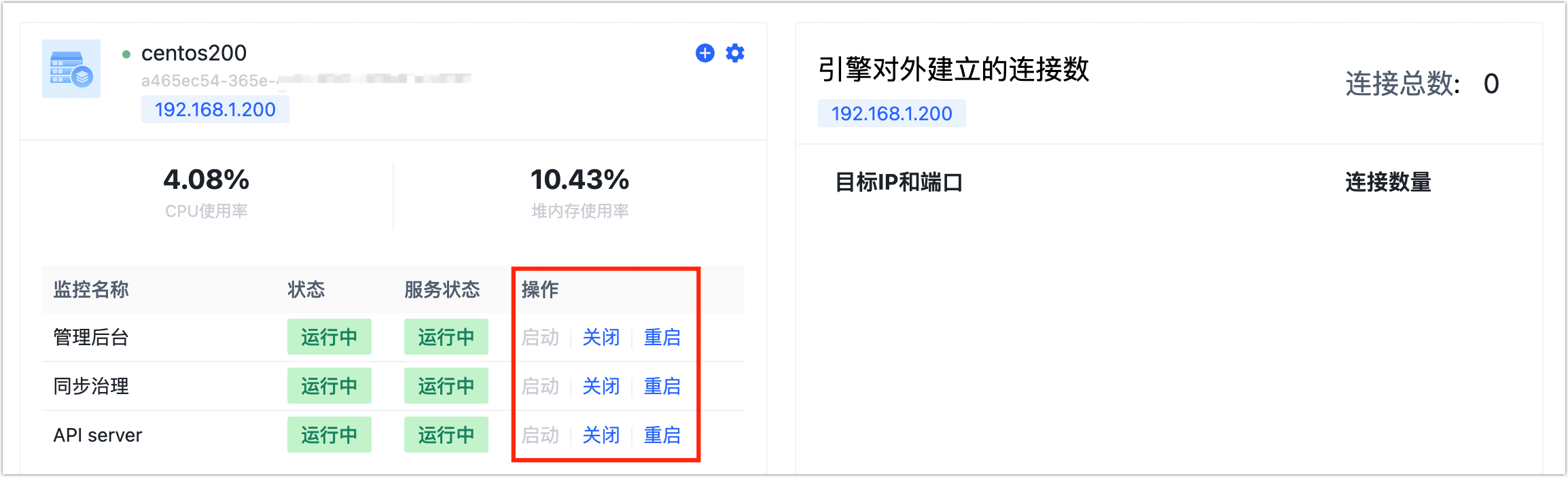
除本方法外,您也可以通过内置 tapdata 命令工具来执行启停操作,该工具的在 TapData 安装目录中,可通过 ./tapdata help 查看命令帮助信息,输出示例如下:
./tapdata help
_______ _____ _____ _______
|__ __|/\ | __ \| __ \ /\|__ __|/\
| | / \ | |__) | | | | / \ | | / \
| | / /\ \ | ___/| | | |/ /\ \ | | / /\ \
| |/ ____ \| | | |__| / ____ \| |/ ____ \
|_/_/ \_\_| |_____/_/ \_\_/_/ \_\
WORK DIR:/root/tapdata
usage: tapdata [option] [subsystem]
Option:
start Start Tapdata
stop Stop Tapdata
restart Restart Tapdata
status Check the running status
init Initialize Tapdata Configuration
resetpassword Reset MongoDB password or certificate key file password
--version Tapdata version
help Show this usage information
Subsystem:
frontend Tapdata management portal
backend Data Processing Node
apiserver API Server Node
如何备份/恢复 TapData?
TapData 运行期间,所有任务配置、共享缓存等关键数据均保存在 MongoDB 中。为保证升级或迁移安全,请通过 MongoDB 备份工具按下列流程对元数据库及工作目录进行备份,并在需要时快速恢复。
备份流程
-
备份前准备。
登录 TapData 所在服务器,进入安装目录,停止服务,高可用部署时,请在每台节点上依次执行。
./tapdata stop -f -
执行下述格式的命令备份元数据库。
mongodump --uri "mongodb://<username>:<password>@<mongodb_host>:<mongodb_port>/<database_name>?authSource=admin" --gzip --excludeCollection="collection_name" -o /backup/tapdata_db_$(date +%F)<username>、<password>:MongoDB 实例的用户名及密码。<mongodb_host>、<mongodb_port>:MongoDB 实例地址及端口(默认 27017)。<database_name>:数据库名(默认 tapdata,如自定义请以实际为准)。--gzip:压缩备份文件,可有效减少备份文件大小。--excludeCollection="collection_name":指定无需备份的集合(如系统日志),从而进一步节约备份耗时和所需的存储空间,可重复指定多个,推荐设置为--excludeCollection="AgentMeasurementV2" --excludeCollection="AlarmInfo" --excludeCollection="ApiCall" --excludeCollection="fs.files" --excludeCollection="fs.chunks" --excludeCollection="Message" --excludeCollection="monitoringLogs" --excludeCollection="InspectDetails" --excludeCollection="DDlTaskHistories" --excludeCollection="Logs"
-
(可选)如需完整备份,例如用于整机迁移场景,可额外备份 TapData 工作目录,示例命令如下:
# 替换 <tapdata_work_dir> 为实际工作目录
tar -czf /backup/tapdata_work_$(date +%F).tar.gz <tapdata_work_dir> -
启动服务,高可用部署时,请在每台节点上依次执行。
# 替换 <tapdata_work_dir> 为实际工作目录
./tapdata start --workDir <tapdata_work_dir>
恢复/回滚流程
-
停止服务,高可用部署时,请在每台节点上依次执行。
./tapdata stop -f -
使用
mongorestore导入元数据,如目标库已存在数据,建议先手动清理或重命名,避免与导入数据冲突。mongorestore --uri "mongodb://<username>:<password>@<mongodb_host>:<mongodb_port>/<database_name>?authSource=admin" <backup_dir>/<database_name><username>、<password>:MongoDB 实例的用户名及密码。<mongodb_host>、<mongodb_port>:MongoDB 实例地址及端口(默认 27017)。<database_name>:数据库名(默认 tapdata,如自定义请以实际为准)。<backup_dir>:备份文件存放的目录(即mongodump -o指定的输出目录)。
-
启动服务,高可用部署时,请在每台节点上依次执行。
# 替换 <tapdata_work_dir> 为实际工作目录
./tapdata start --workDir <tapdata_work_dir>
如果是整机迁移进行数据恢复的场景,需要在启动服务前,恢复 TapData 工作目录至新服务器上。
如何执行滚动升级?
从 3.3.0 版本开始,TapData 支持滚动升级功能,相较于普通的停机升级方式,可帮助您缩短升级时间窗口,进一步降低业务影响,具体步骤如下:
- 升级前后两个版本相兼容,同时推荐任务进入增量阶段或在业务低峰期执行。
- 升级 TapData 服务前,推荐通过
mongodump命令或其他方式,对 TapData 依赖的元数据库进行备份。
-
登录 TapData 所属的服务器,保持原版本的 TapData 服务处于运行中。
-
下载并解压 3.3.0 版本安装包,然后进入安装包目录中。
-
执行下述格式的命令,完成滚动升级流程,升级完成后将提示:
Update finished. All Task are running.。./tapdata upgrade --source <old_version_path>old_version_path:老版本 TapData 所安装的目录,示例如下:
./tapdata upgrade --source /root/320/tapdata/提示如果升级过程中遇到错误后,再次执行升级命令,可以接续上次升级过程,如需重置升级状态命令,可执行
./tapdata upgrade reset。 -
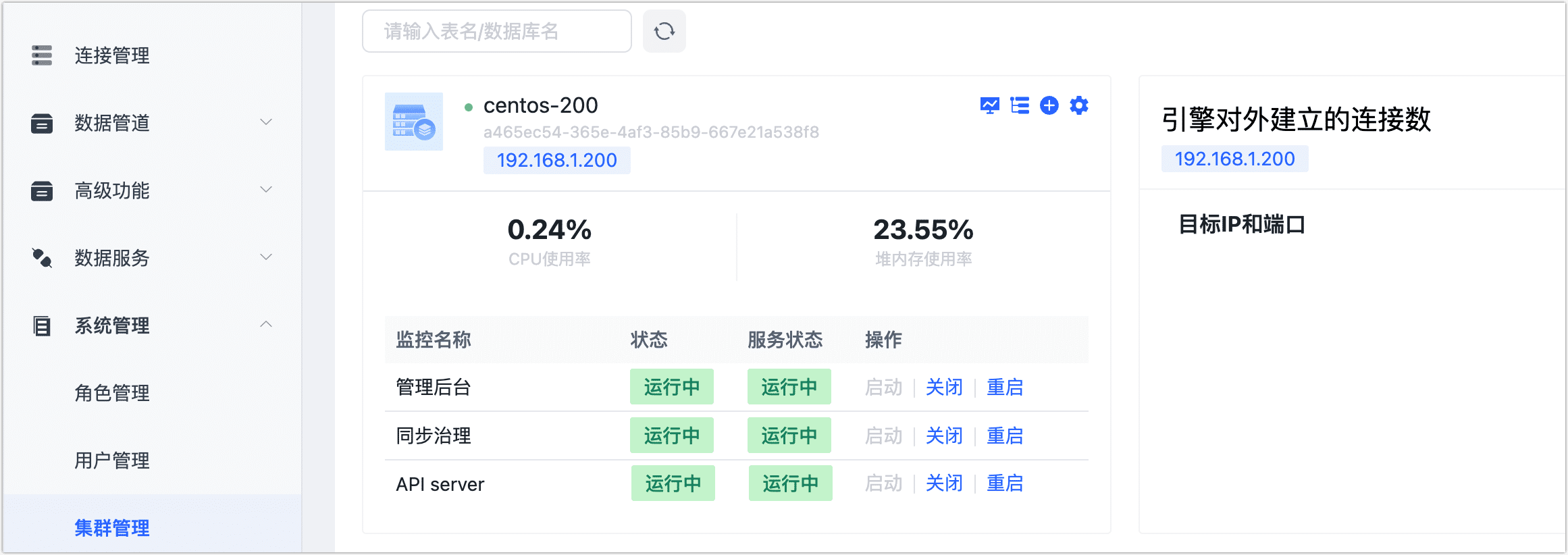
升级完毕后,登录 TapData 平台,单击右上角的用户名并选择系统版本确认已升级成功。
-
在 TapData 平台左侧导航栏,选择系统管理 > 集群管理,确认服务都已正常运行。
如何扩容 TapData 集群?
当现有集群面临性能瓶颈、资源使用接近上限或需要提高系统容错能力和高可用性时,可对集群进行扩容操作,具体操作流程如下:
-
完成新机器的环境初始化。
-
登录至服务器,依次执行下述命令完成文件访问数、防火墙等系统参数设置。
ulimit -n 1024000
echo "* soft nofile 1024000" >> /etc/security/limits.conf
echo "* hard nofile 1024000" >> /etc/security/limits.conf
systemctl disable firewalld.service
systemctl stop firewalld.service
setenforce 0
sed -i "s/enforcing/disabled/g" /etc/selinux/config -
安装 Java 17 版本。
yum -y install java-17-openjdk -
设置系统时间。
# 方式一:use ntpdate
# nptdate -u cn.ntp.org.cn
crontab -e
# 最后一行添加
* */1 * * * ntpdate -u ntp1.aliyun.com
# 方式二:date -s 指定
date -s '10:34:06'
# 系统时间同步到硬件,防止系统重启后时间被还原
hwclock -w
-
-
下载 TapData 安装包(可联系我们获取),将其上传至待部署的设备中。
-
在待部署的设备上,执行下述格式的命令,解压安装包并进入解压后的路径。
tar -zxvf 安装包名&&cd tapdata例如:
tar -zxvf tapdata-release-v2.14.tar.gz&&cd tapdata -
在待部署的设备上,完成扩容操作。
-
复制集群已有节点中,TapData 工作目录下的 application.yml 文件至待部署设备中的 TapData 工作目录,然后注释或删除该文件中的 uuid 所在行。
-
上传 License 文件至 TapData 工作目录。
-
启动并扩容所需的服务。
# 扩容 TapData 管理服务
./tapdata start frontend
# 扩容 TapData API 服务
./tapdata start apiserver
# 扩容 TapData 引擎服务
./tapdata start backend
-
-
启动成功后,可登录 TapData 平台,在系统管理 > 集群管理中查看各服务的状态。
TapData 依赖的 MongoDB 数据库如何保障高可用?
避免使用单节点架构,可采用副本集部署架构来保障高可用,例如采用三节点的副本集架构时,其中一个节点作为 Primary 节点,其他节点作为 Secondary 节点。
如果已采用单节点架构,您可以将其转换为副本集架构。
在副本集中,写入 Primary 节点的数据会自动同步至 Secondary 节点上,当 Primary 节点故障或不可用时,副本集会自动选举一个新的 Primary 节点,从而保证数据库的可用性和数据的完整性,最大程度地减少数据库出现故障的时间和影响。
您可以登录 MongoDB 数据库,通过 rs.status() 命令查看副本集状态和各节点的状态信息。更多介绍,见 Replication。
如何查看运行日志?
在 2.15 之前版本,日志分散存放在 TapData 安装目录中的各文件夹中,从 2.15 版本开始,日志信息集中存放在安装目录下的 logs 目录中。
TapData 配置文件存放位置?
TapData 配置文件 :application.yml 存放在 TapData 的按照目录中,它保存了关键配置信息,例如可用内存配置、服务端口、MongoDB 数据库连接信息等。
如何调整 Java 可用的内存大小?
默认情况下,可用的内存为 4 GB,如需调整,可前往 TapData 安装目录下的配置文件 application.yml,编辑该文件,根据服务器的可用内存和任务负载调整内存配置信息,例如配置为 tapdataJavaOpts: "-Xms8G -Xmx16G",即表示初始内存 8G,最大内存 16G,示例如下:
tapdata:
cloud:
accessCode: ""
retryTime: '3'
baseURLs: ""
mode: cluster
conf:
tapdataPort: '3030'
backendUrl: 'http://127.0.0.1:3030/api/'
apiServerPort: '3080'
apiServerErrorCode: 'true'
tapdataJavaOpts: ""
SCRIPT_DIR: etc
reportInterval: 20000
uuid: 093288a0-9ab9-4752-bd1c-7163aea4a7ba
Decimal128ToNumber: 'false'
tapdataTMJavaOpts: '-Xmx8G -Xms16G'
如果内存分配较小,但任务负载较多,Java 程序可能因可用内存不足而不停地执行垃圾回收操作,引起 CPU 使用率激增。
管理端子进程不停重启,如何排查?
- 检查作为 TapData 存储引擎的 MongoDB 是否可以正常连接,且版本需为 4.0 及以上。
- 执行
./tapdata restart frontend,随后可以在 logs 目录中找到 frontendDebug.log 文件并查看,通过日志的报错信息分析具体原因。
任务调度的规则是什么?
TapData 提供多层次的任务调度机制,包括默认的基于任务数量的调度策略、灵活的引擎(Flow Engine)分组调度,以及基于标签的启动优先级控制。这些机制确保任务高效、均衡地运行在合适的引擎上,避免资源浪费和单点过载。
使用建议:日常场景优先使用基础调度机制,简单高效;对性能或隔离有要求的任务,推荐启用引擎分组调度;大批量启动任务时,利用标签控制顺序,避免重要任务被阻塞。
基础调度机制(默认)
系统默认采用基于任务数量的均衡策略,自动将任务分配到合适的引擎:
- 启动调度:任务启动时,系统查询所有存活引擎的当前运行任务数量,优先调度到任务数量最少的引擎。
- 故障转移:引擎心跳超时或任务接管失败时,立即触发重新调度,将受影响任务转移到当前任务数量最少的存活引擎。
- 任务调度均衡:当扩缩容、节点恢复或长期运行导致任务分布不均时,可通过任务调度均衡重新分配可迁移任务。
此机制适用于大多数场景,无需额外配置,即可实现高效资源利用。
引擎分组调度
为满足不同业务对性能、隔离或专用资源的需求,TapData 支持引擎分组调度。
配置步骤:
进入集群管理页面,切换到组件视图,根据机器性能、业务线等维度创建分组(如“高性能组”或“业务A专用组”),并将相应引擎加入。
调度规则:
- 在创建连接或任务时,可选择特定分组进行调度。
- 系统仅在选定分组内的引擎中调度任务。
- 分组内仍遵循任务数均衡原则(优先选择任务数量最少的引擎)。
- 如果分组内所有引擎不可用,任务进入等待状态,并触发告警通知,便于管理员及时介入。
任务标签调度
任务标签主要用于分类管理和批量操作场景下的启动顺序控制。
配置步骤:
在任务管理页面,为任务设置标签(优先级范围 P1~P6)。
调度规则:
- 优先级范围:P1 ~ P6,数字越小,优先级越高,启动顺序越靠前。
- 批量启动多个任务时:系统按标签优先级从高到低依次执行。
- 无标签任务:按选中顺序依次启动,如同时多选多个无标签任务,系统会并发启动这些任务。
- 标签调度仅控制任务的启动顺序,不影响运行时的引擎分配。
- 批量启动时,TapData 在下发启动指令后即视为“已启动”,不会等待任务状态变为“运行中”。
TapData 如何实现高可用?
您可以在多台机器上部署 TapData 以实现高可用,某个节点出现异常时,其余节点可继续提供服务,进入增量的任务会断点续传,任务可自动均衡调度分配。
TapData 所依赖的 MongoDB 库异常,如何排查?
MongoDB 数据库异常可能有多种不同的原因,通常的排查流程如下:
-
检查硬件资源,例如 CPU、内存、磁盘空间,如果资源不足或者磁盘空间已经用尽,可能会导致数据库异常。
-
检查 MongoDB 日志文件,尤其是最近几次启动的日志文件。日志文件通常会记录警告、错误、异常等信息,这些信息可以帮助确定问题的来源。
您也可以通过 mongo shell 登录上数据库查看,更多介绍,见 getLog。
-
登录上 MongoDB 数据,执行
db.serverStatus()命令查看当前数据库的状态及统计信息,分析是否存在性能等问题。更多介绍,见 serverStatus。 -
尝试使用 MongoDB 自带的工具进行故障排查,例如使用
mongotop命令查看各个集合的读写操作情况,使用mongostat命令查看服务器的活动状态。
TapData 所依赖的 MongoDB 库中,库名是什么,集合有哪些?
采用的数据库名称为 tapdata,您可以通过 mongo shell 登录上数据库查看具体包含的集合,示例如下:
# 进入 tapdata 数据库
use tapdata;
# 查看当前数据库中有哪些集合
show collections;
# 查看指定集合中的数据
db.ClusterState.find();
主要关注的集合如下,随着版本更新,可能会有所变化:
- ClusterState: 集群状态信息
- ClusterStateLog: 集群状态日志
- Connections: 连接源属性信息
- DatabaseTypes: 支持的数据源类型(字典数据)
- DataCatalog: 数据目录信息
- DataFlows: 任务属性状态信息
- DataFlowStage: 任务属性阶段信息
- DeleteCaches: 缓存的删除数据
- Events: 任务执行的通知事件
- Jobs: 任务执行过程信息
- LineageGraph: 数据地图
- Logs: 日志信息
- Message: 消息
- MessageQueue: 消息队列
- MetadataDefinition: 元数据定义
- MetadataInstances: 元数据信息
- Modules: 数据发布 - API 发布信息
- nodeConfig: 自定义节点配置信息
- Permission: 权限信息(字典数据)
- Role: 角色
- RoleMapping: 角色有那些权限
- ScheduleTasks: 任务调度信息
- Settings: 系统设置信息
- User: 用户信息
- UserLogs: 用户操作信息
- Workers: 进程信息
- License: License 信息
- TypeMappings: 类型映射
如何确认告警邮件是否发送成功
TapData 支持通过 SMTP 协议发送告警邮件,帮助用户及时了解运行异常,保障任务的稳定运行。
在实际使用中,如果接收端用户反馈未收到告警邮件,作为管理员可以通过以下步骤排查邮件发送情况:
-
登录 TapData 所依赖的 MongoDB 数据库。
-
进入
tapdata数据库,执行以下命令:db.Events.find().sort({_id: -1})此命令将按时间倒序查看最新的告警事件记录。
-
分析关键字段:
- 如果记录中包含
successful,表示邮件已发送成功。 - 如果记录中包含
failed,表示邮件发送失败,此时可以查看fail_message字段的值,分析具体失败原因。
- 如果记录中包含
哪些是高危操作?
通过仔细审查系统高危操作,及时发现和应对潜在威胁,确保系统操作上的数据安全、完整性和可用性。深入理解各项高危操作,有助于建立可靠的平台管理制度、权限管理制度,提高对系统各种安全挑战的识别能力,从而为企业的数据处理流程、平台管理规范奠定基础。
常见的高危操作如下:
- 连接管理
- 删除数据源连接:如果有任务使用到此数据源,为避免误删除,当执行删除操作会提示该连接被任务引用。
- 编辑数据源连接:如果数据源的参数设置不正确可能导致该连接失效,正在引用该数据源的任务会使用之前的参数而不受影响,但是新任务或将任务重置后可能引发报错。
- 数据复制/数据转换任务
- 重置任务:该操作会将任务重置为初始状态,清空历史监控数据,后续启动任务时需要重新执行全量数据同步。
- 数据重复处理策略:在目标节点的设置中,设置不同的数据重复策略会影响目标表的结构和数据,例如选中清除目标端原有表结构和数据,在任务启动后,TapData 将清除目标端的表结构和所有数据,同步源端新的表结构和数据。
- 设置数据写入策略:在目标节点高级设置中,如选择为追加写入,Tapdata 将仅处理插入事件,丢弃更新和删除事件,请基于业务需求谨慎选择,避免带来数据不一致的风险。
- 设置同步索引:当数据复制任务用于仅同步增量数据的场景中,即保留目标表数据,如果目标表的数据规模较大,同步索引操作可能会影响目标库的整体性能。
- 设置更新条件字段:如果目标没有索引,会按照更新条件字段创建索引。
- 任务 Agent 设置:在右上角的任务设置中,如果手动指定 Agent ,后续任务如果是复制此任务时此配置项会保持不变,可能造成单个 Agent 的压力过大,推荐设置为平台自动分配。
- 数据服务
- 删除或者下线 API,将导致该 API 不可用。
- 系统管理
- 在管理集群时,应仅在服务出现异常时,才对相关服务执行关闭或重启操作。
任务发生异常,如何排查?
当任务发生异常时,可通过以下步骤进行排查:
-
登录 TapData 平台,找到目标任务,查看任务的具体报错信息,根据报错信息(如表不存在)进行调整。
-
登录 TapData 所属机器,进入 TapData 安装目录查看更多日志信息。
-
如果无法登录 TapData 平台,可在其所属机器上执行
./tapdata status,查看服务是否正常运行。./tapdata status
_______ _____ _____ _______
|__ __|/\ | __ \| __ \ /\|__ __|/\
| | / \ | |__) | | | | / \ | | / \
| | / /\ \ | ___/| | | |/ /\ \ | | / /\ \
| |/ ____ \| | | |__| / ____ \| |/ ____ \
|_/_/ \_\_| |_____/_/ \_\_/_/ \_\
WORK DIR:/root/tapdata
Tapdata was stopped.
Tapdata Engine PID:
Tapdata Management PID:
API Server Controller PID:
API Server Instances PID:如上述示例所示,服务处于停止状态,此时可执行
./tapdata start启动相关服务。